What Are Evals
Evals are measurements of how a skill behaves. You write a prompt, declare what should happen, run the skill, and grade the result against your expectations. They are how you know your skill works, that regression tests caught problems, and that a description fires on the right queries.
Why Evals Matter
Section titled “Why Evals Matter”A skill is a contract. Its description claims when Claude should invoke it. Its body claims a behavior. Evals turn both claims into a test suite you can run after editing a skill, after upgrading the model, or before publishing a module. Every run lands on disk. You can read the transcript, inspect the artifacts, and trust the verdict because the grading is reproducible.
How the Test Types Flow
Section titled “How the Test Types Flow”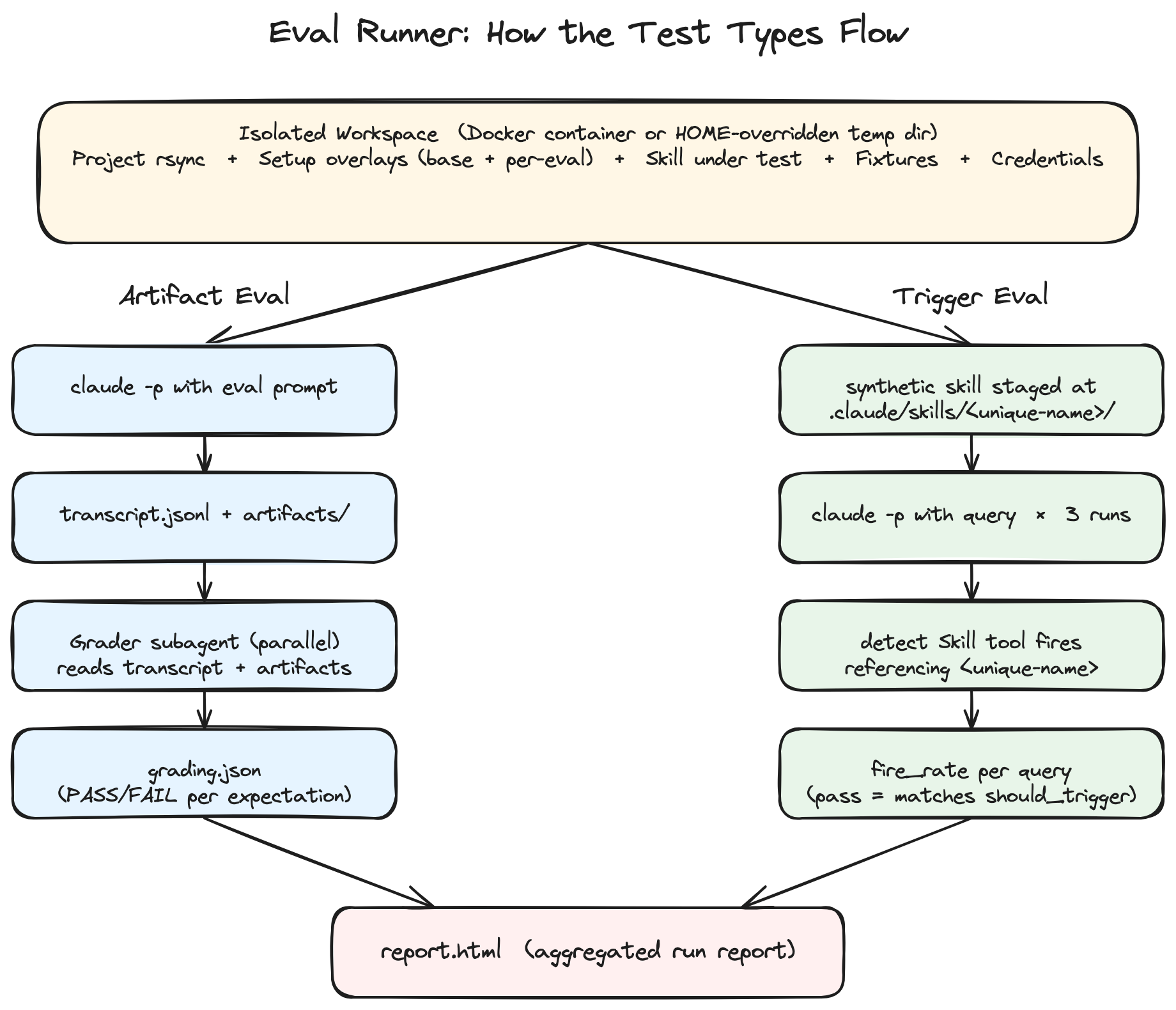
Both test types share the same isolated workspace setup, then split into parallel pipelines, and converge into a single aggregated report.
Two Types of Evals
Section titled “Two Types of Evals”BMad evaluates two questions independently.
Artifact Evals: Did the Skill Do the Right Thing?
Section titled “Artifact Evals: Did the Skill Do the Right Thing?”The runner sends a prompt to the skill in an isolated workspace and captures everything that happened: the full stream-JSON transcript (every tool call the skill made, every assistant message) and every file the skill wrote. A grader subagent then scores your expectations against the captured run.
Artifact evals live in evals.json. Each entry has a prompt, optional fixture files to stage in the workspace, and a list of expectations graded independently.
Multi-step workflow skills run end-to-end inside the single claude -p invocation when the prompt puts them in headless mode. The skill executes its full internal flow (subagent calls, polish passes, finalize sequence) and all of it shows up in the captured run.
Trigger Evals: Does the Description Fire on the Right Queries?
Section titled “Trigger Evals: Does the Description Fire on the Right Queries?”A skill is invisible if Claude never invokes it. The trigger runner places a synthetic copy of your skill in a clean workspace, sends candidate user queries, and watches whether the Skill tool actually fires on each one.
Trigger evals live in triggers.json. Each entry has a query and a boolean should_trigger. The runner repeats each query (3 times by default) and reports a fire rate per query.
What Every Artifact Eval Captures
Section titled “What Every Artifact Eval Captures”Every artifact eval, regardless of style, lands the same shape on disk:
| File | Contents |
|---|---|
prompt.txt | The eval’s prompt verbatim |
transcript.jsonl | Stream-JSON: every tool call, every assistant message |
artifacts/ | Every file the skill wrote inside its workspace |
metrics.json | Tool-call counts, timing, output sizes |
grading.json | Per-expectation PASS/FAIL with cited evidence |
You always have both the transcript and any files the skill wrote. Your expectations choose which to grade against. Trigger evals are simpler: the stream is parsed in real time for Skill tool fires and the per-query fire rate is saved to triggers-result.json.
Two Ways to Grade an Artifact Eval
Section titled “Two Ways to Grade an Artifact Eval”You can mix both styles in the same eval. Most well-tested skills do.
Output Grading
Section titled “Output Grading”Look at the files the skill produced. Assertions check structure, content, and fidelity to inputs.
Use output grading when:
- The deliverable is a file (brief, PRD, plan, doc) and you care that it’s correct
- You can write a complete pre-discovery prompt so the skill has nothing to ask about
- You want regression coverage on drafting, format, and extraction
Examples:
- “brief.md word count is between 250 and 1500”
- “decision-log.md captures the pricing decision with rejected alternative and rationale”
- “frontmatter contains title, status, created (ISO 8601), updated (ISO 8601)“
Transcript Grading
Section titled “Transcript Grading”Look at the captured stream-JSON to see what the skill did internally. The grader scans for specific tool calls, checks the order things happened, walks side-artifacts (decision logs, addenda, distillates), and checks file timestamps.
Use transcript grading when:
- The skill enforces a protocol (decision log, polish phase, finalize sequence)
- The skill has read-only intents (Validate must not write any files)
- You need to catch regressions where drafting still works but the discipline went soft
Examples:
- “transcript contains a Skill tool call invoking bmad-editorial-review-prose”
- “polish-phase Skill calls occur after the brief body Write and before the final JSON status block”
- “input fixture brief.md is byte-identical after the run; no Write or Edit tool calls targeted it”
A Worked Example
Section titled “A Worked Example”The bmad-product-brief skill in the BMad Method repository ships a complete eval suite that uses every feature in this guide. It mixes output grading and transcript grading in the same suite, stages dependency skills via setup overlays, includes a read-only Validate intent that asserts no fixtures were touched, and runs trigger evals across positive and negative queries.
| What you can learn from it | Where to look |
|---|---|
| Output grading assertions | evals/bmm-skills/bmad-product-brief/evals.json A1-A8 |
| Transcript grading assertions | evals/bmm-skills/bmad-product-brief/evals.json B1-B8 |
| Trigger queries (positive/negative) | evals/bmm-skills/bmad-product-brief/triggers.json |
| Setup overlays for dependencies | evals/bmm-skills/bmad-product-brief/setup/ |
See Eval Format for the complete schema and a deeper tour of the suite.
Best Practices for Evals That Hold Up
Section titled “Best Practices for Evals That Hold Up”- Discriminating expectations. Each assertion should fail for a wrong output, not just an absent file. “brief.md exists” passes for an empty file. Pair existence checks with content checks.
- Specific facts over vibes. “incorporates at least 2 specific findings from section X” beats “is high quality.” Concrete claims are gradable.
- Negative assertions. “does not introduce content from unrelated sections” catches drift that positive assertions miss.
- Bidirectional fidelity. For skills with side-artifacts, assert in both directions: every entry in the log appears in the brief, and no claim in the brief is absent from the prompt or log.
- Read-only enforcement. For Validate-style intents, assert that input fixtures are byte-identical after the run and that no Write or Edit tool calls targeted them.
- Trust the grader’s pushback. Graders are instructed to flag weak assertions. When they do, fix the assertion rather than ignoring the note.
Next Steps
Section titled “Next Steps”For practical run instructions, see Run Evals Against a Skill. For the complete file format, see Eval Format. For why isolation matters, see Why BMad Eval Runner.